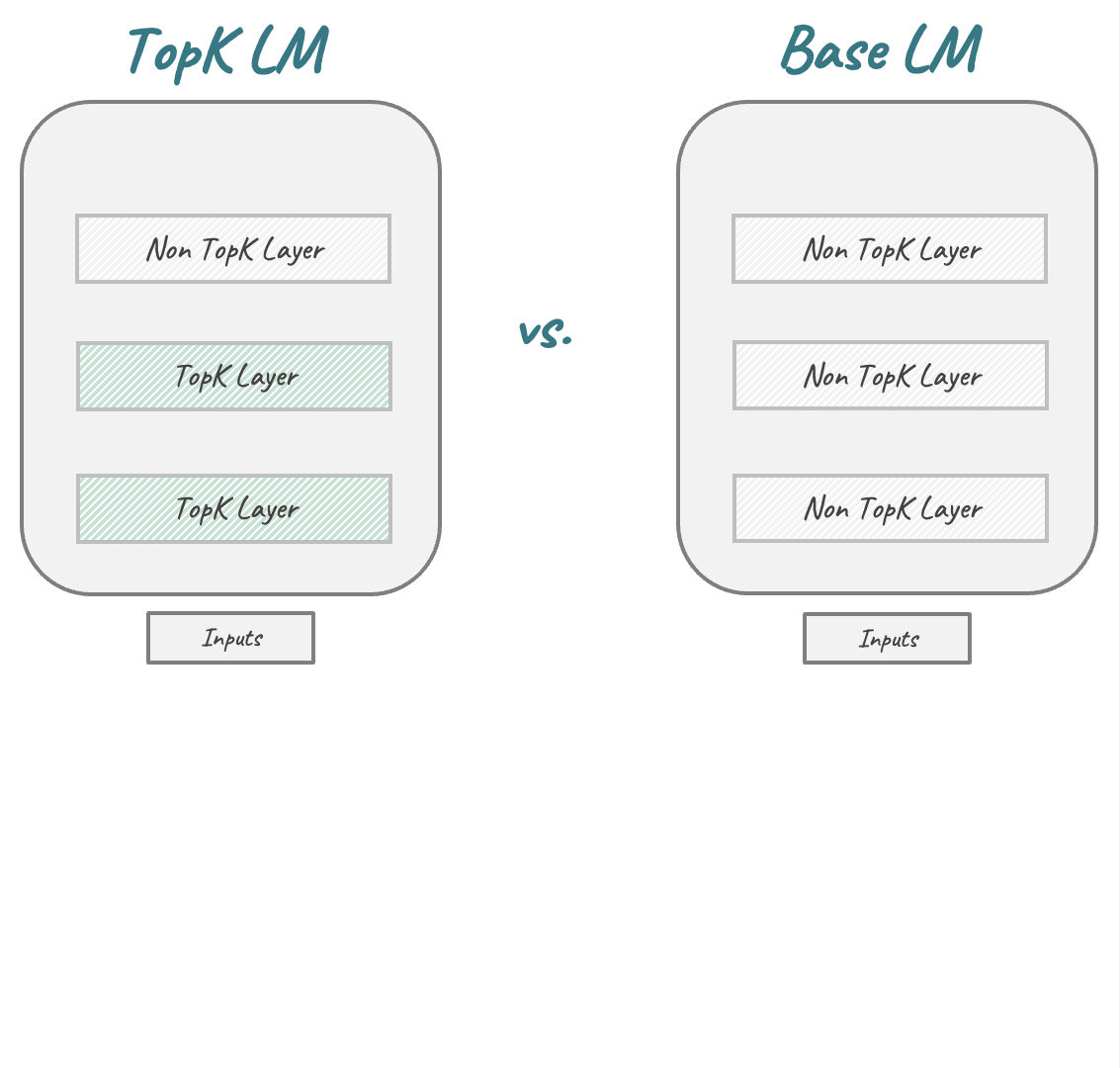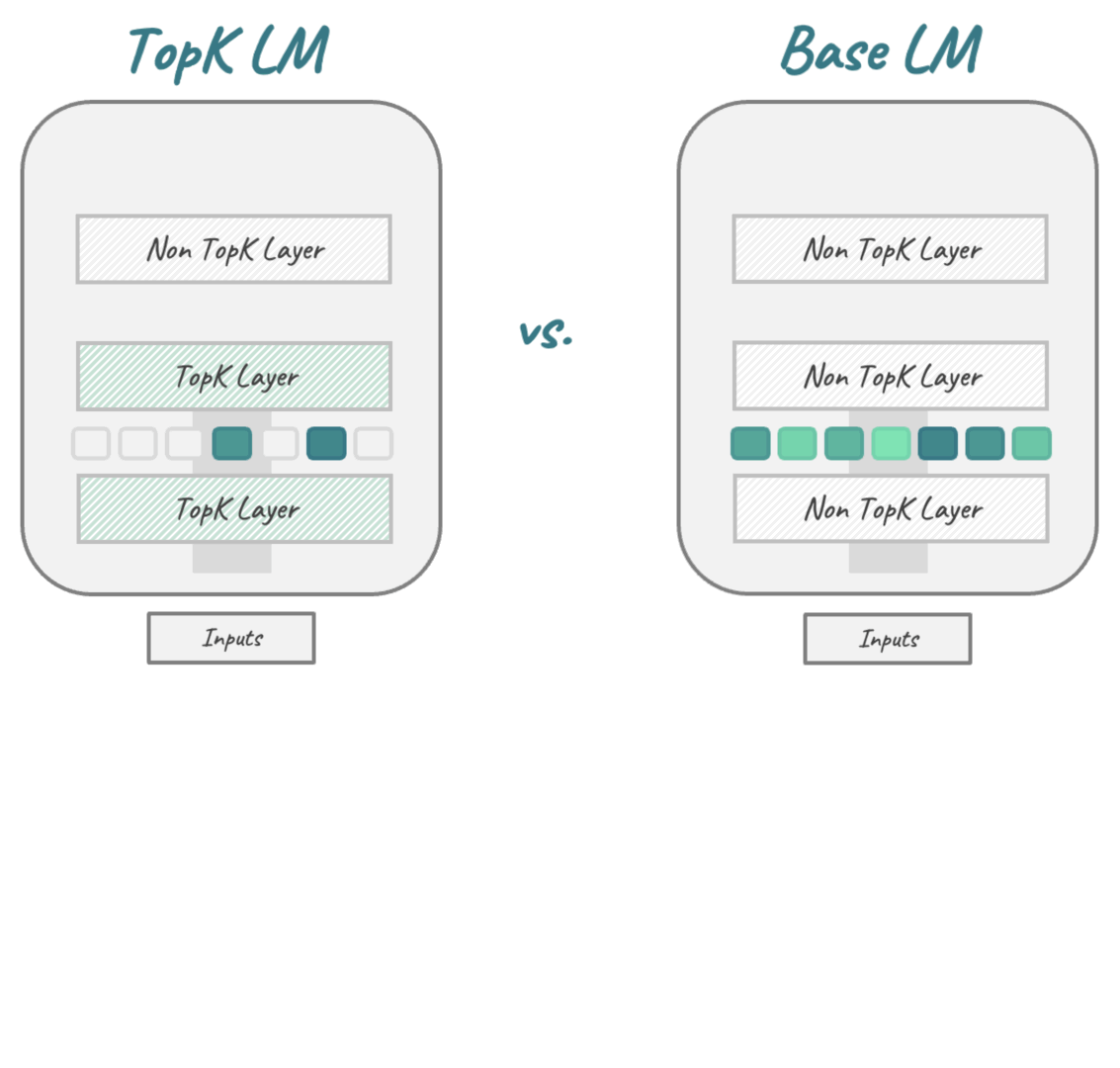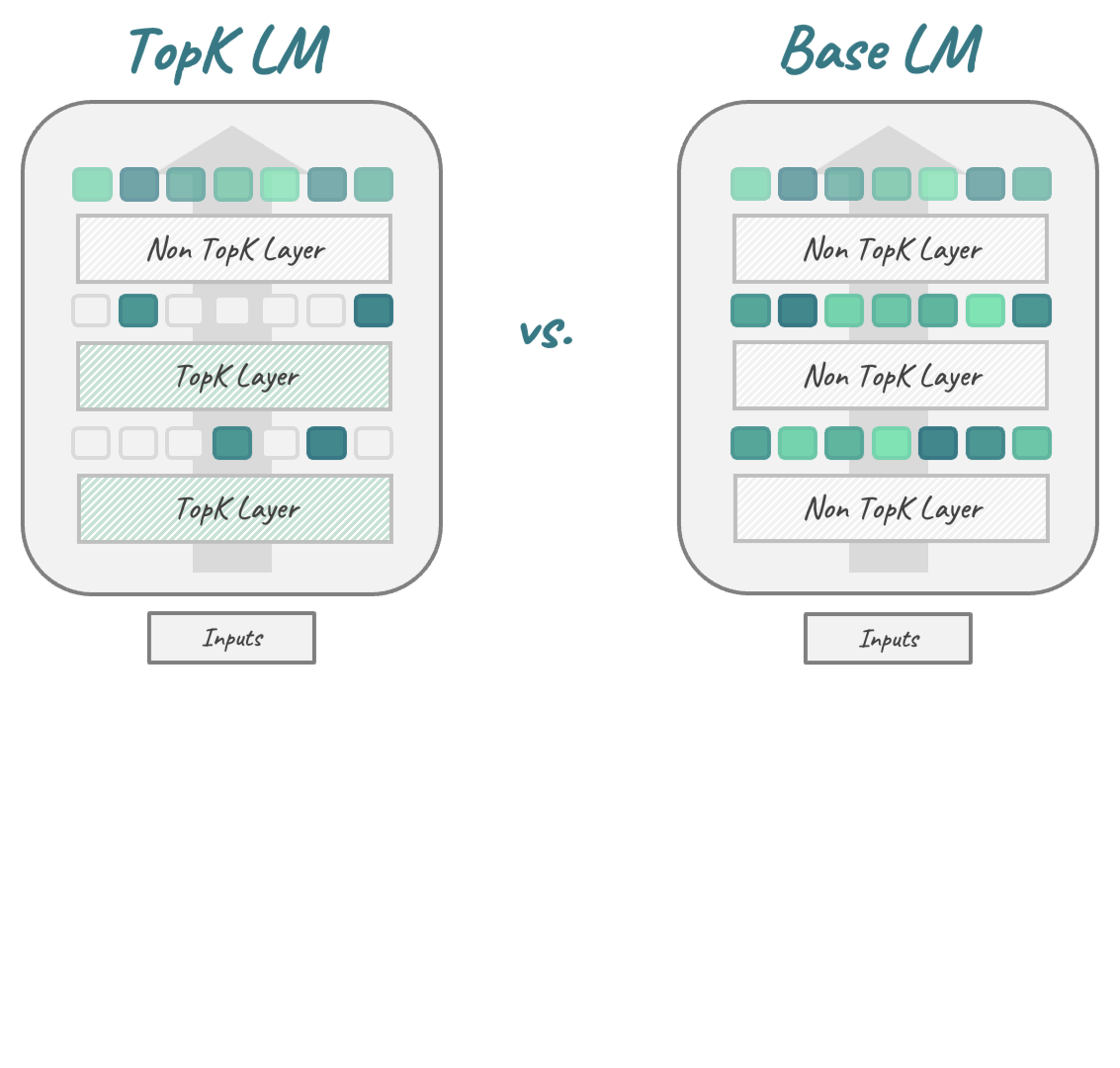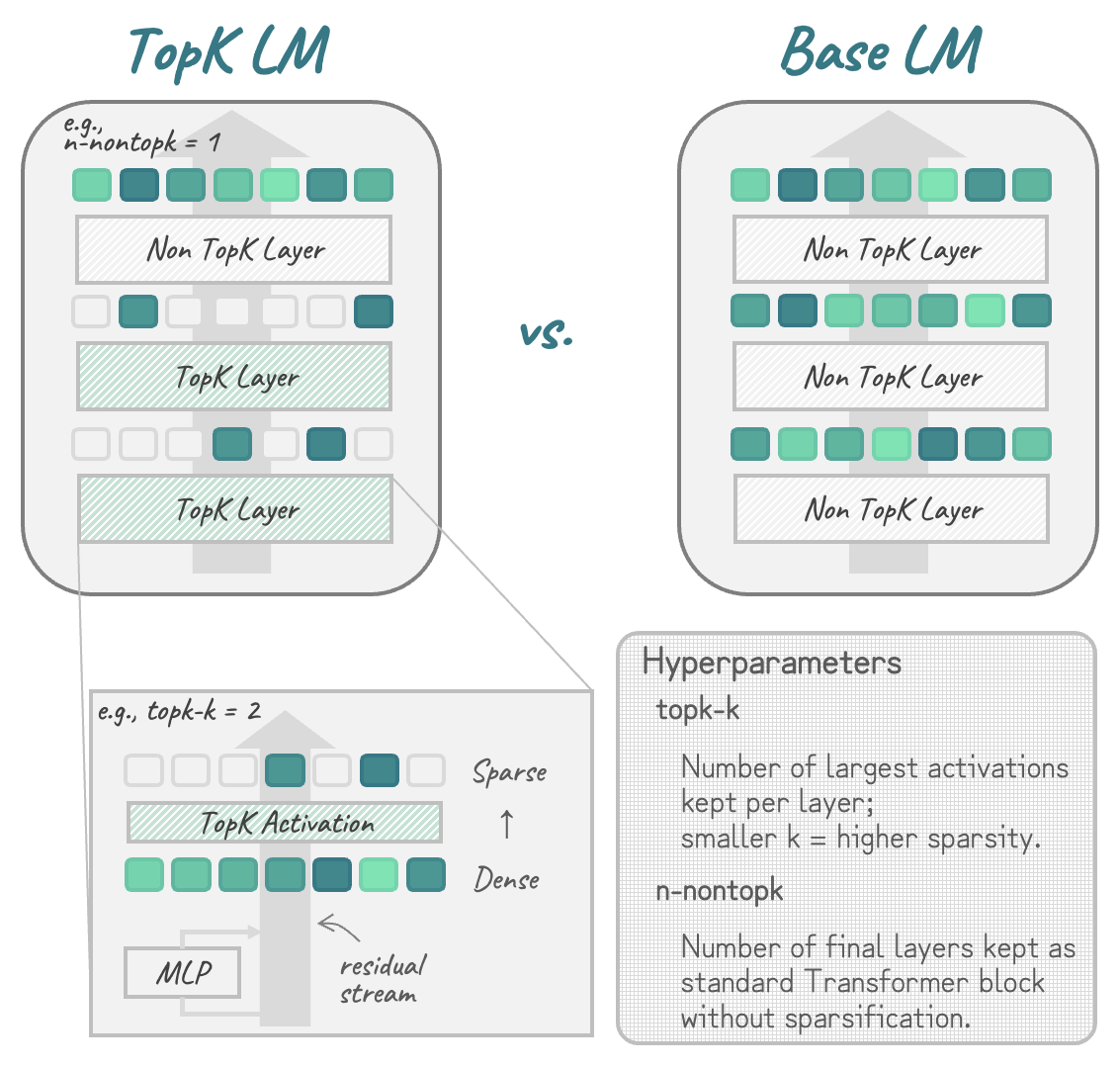
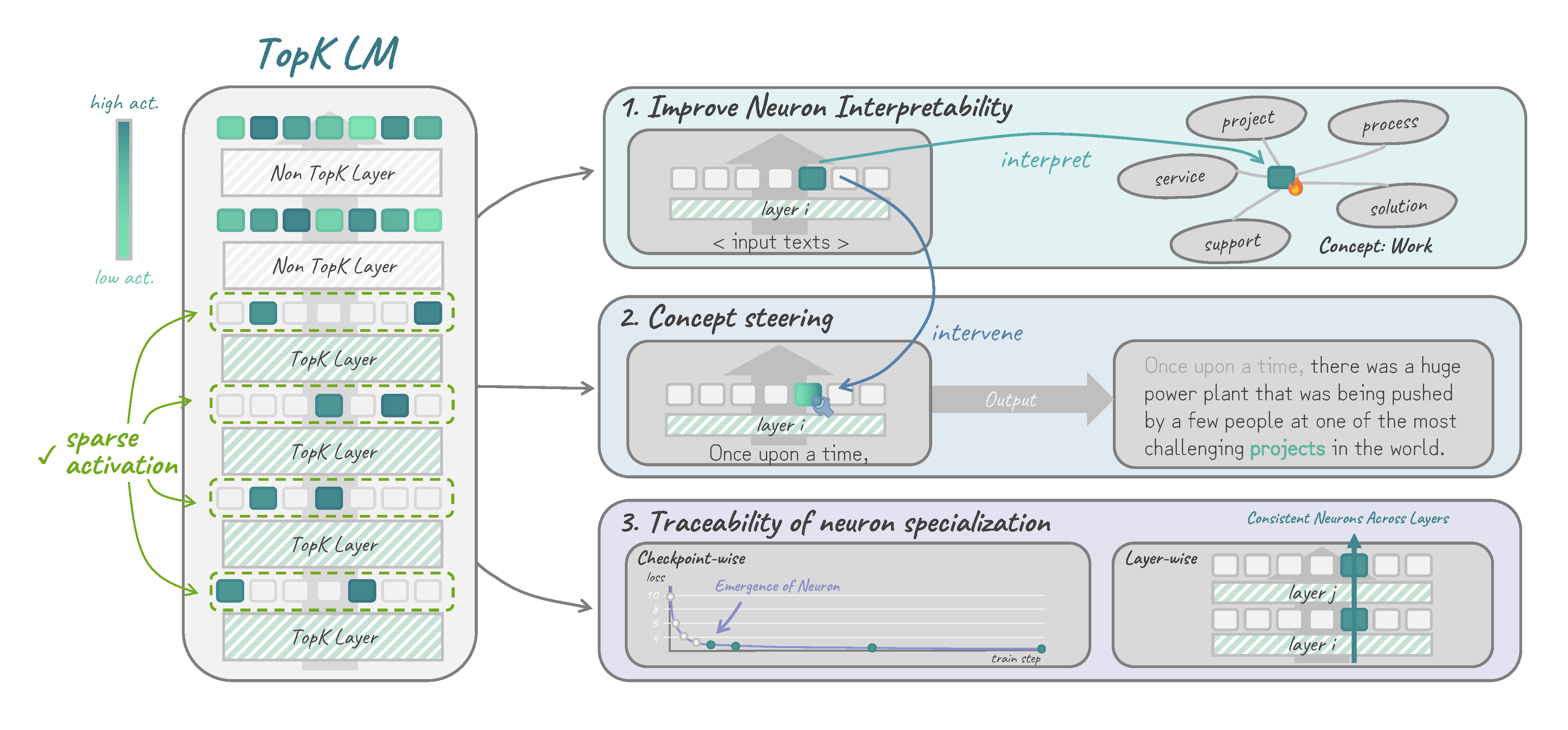
We replace the activation function in Transformer-based LMs with the TopK function,
resulting in SAE-like highly interpretable sparse activations.
Why Sparsely-activated LMs?
Sparse Autoencoders (SAEs) are one of go-to tools for interpreting the hidden states of LMs, since their sparse activations often (but not always) exhibit interpretable patterns. However, SAEs are trained post-hoc, which comes with several drawbacks such as additional training cost, inconsistency of learned SAE features across random seeds, and the possibility that SAEs do not learn all features represented in the underlying LM.
That's where we asked: Why don't we just put the SAE into the LM right from the start? By replacing the LM's original activation function with the TopK activation function popularized by SAEs, we get a new LM architecture that combines the performance benefits of transformer-based LMs with the interpretability advantages of sparse autoencoders, without requiring post-hoc training.